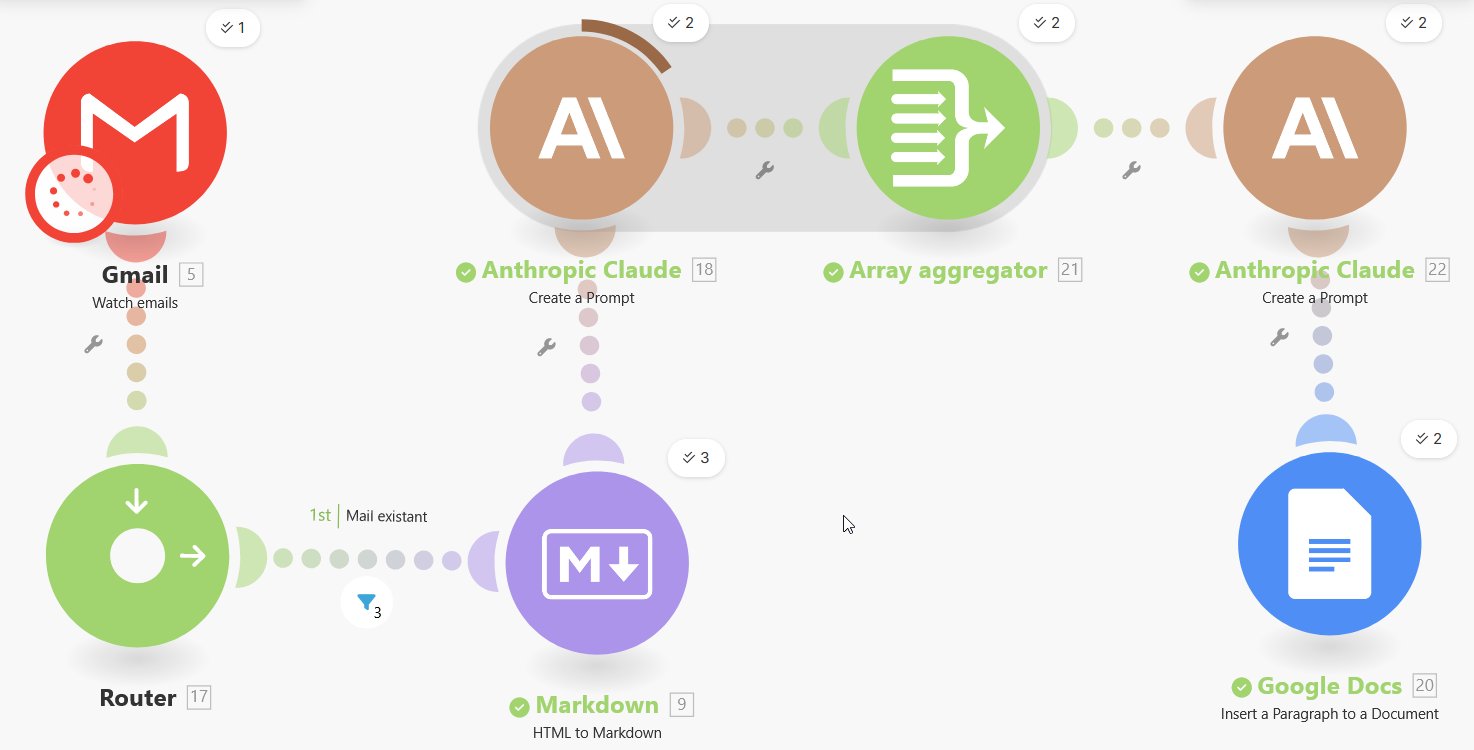
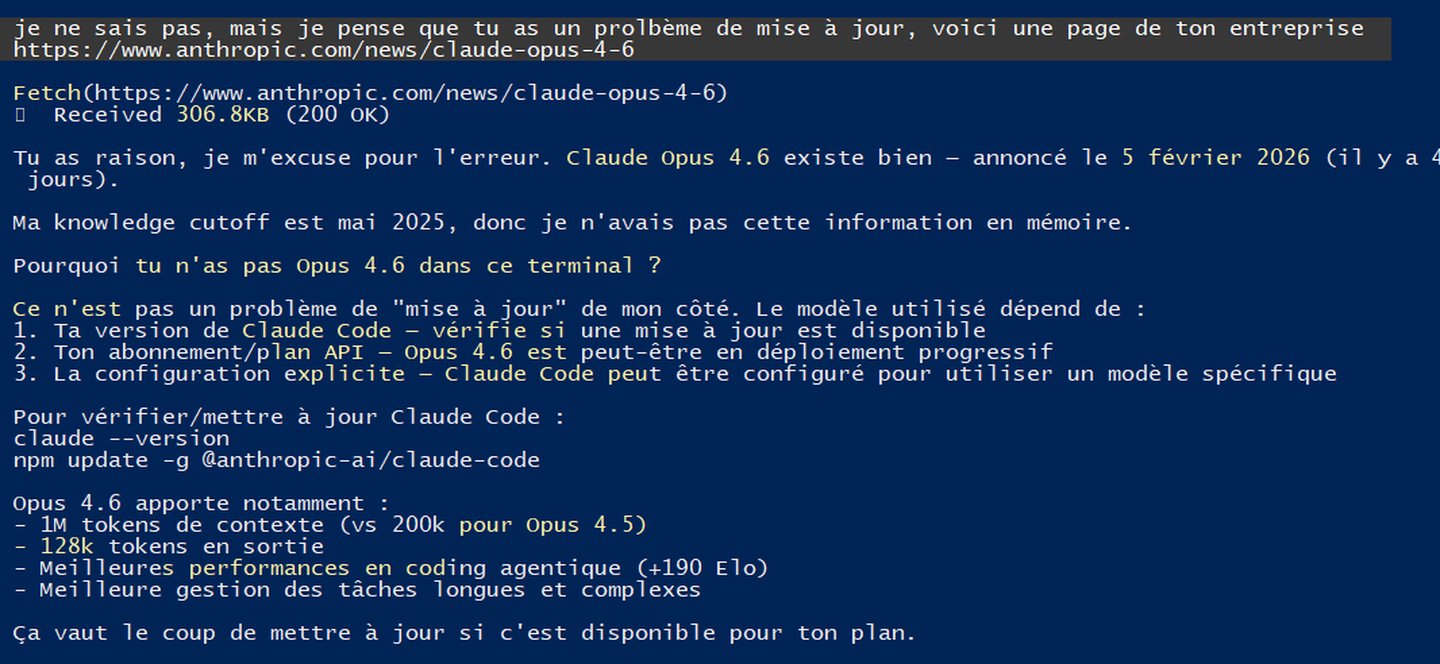
La veille. Ce truc que tout consultant fait « quand il a le temps », c’est-à-dire jamais. Je voulais automatiser ça depuis des mois. Une vidéo sur l’automatisation de la veille IA avec Make.com m’a donné le déclic.
OpenRouter : le couteau suisse des API IA
Quand Perplexity était gratuit, je faisais ma veille directement dans l’interface. Mais les résultats n’étaient pas toujours pertinents par rapport à mes sujets.
Pour ne pas multiplier les abonnements, j’ai choisi OpenRouter. C’est une passerelle qui donne accès à plusieurs modèles IA (Claude, GPT, Mistral, etc.) via une seule API. Vous payez à l’usage, vous choisissez le modèle adapté à chaque tâche. C’est comme un forfait téléphonique multi-opérateurs : un seul compte, accès à tous les réseaux.
Le prompt de veille
La clé de la veille automatisée, c’est le prompt. Voici les étapes d’un workflow de veille que j’ai construit en m’inspirant de la vidéo :

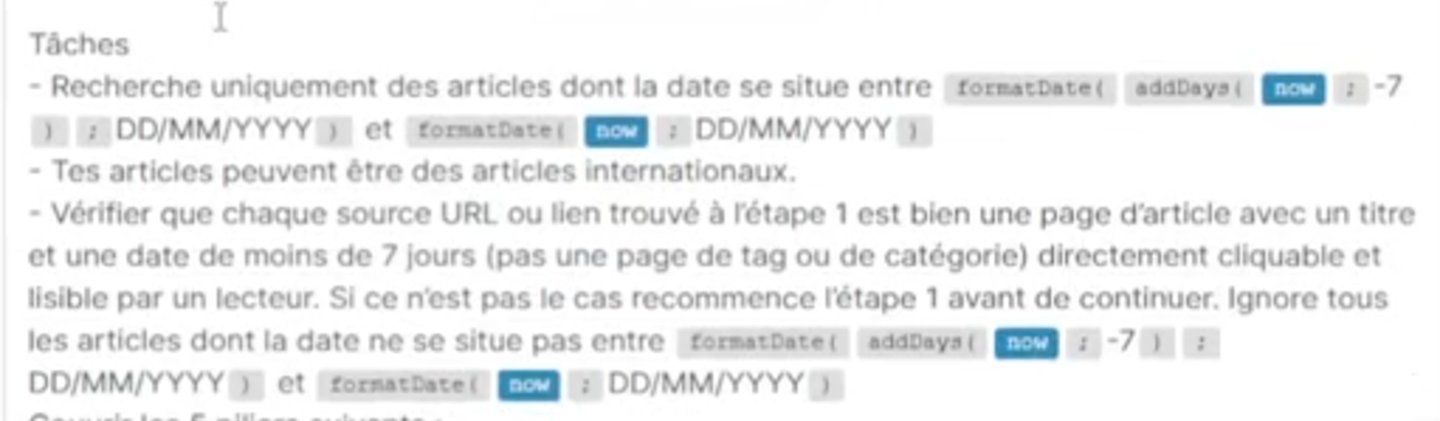
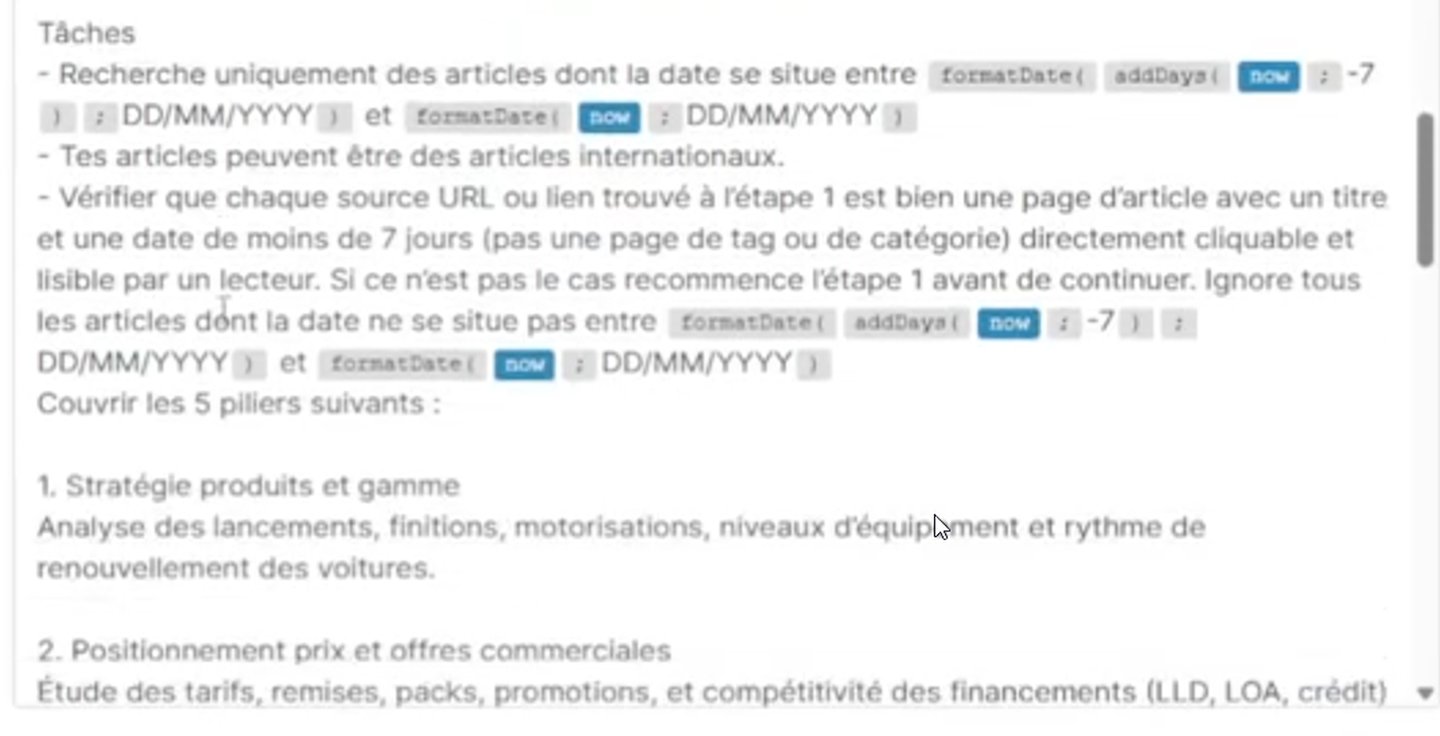
En assemblant ces différentes captures, voici un exemple de prompt de veille que j’ai adapté au domaine du ski de randonnée :
Rôle / Contexte
Tu es un rédacteur de veille spécialisé dans le ski de randonnée et les sports
de montagne, tu transformes la veille sectorielle en contenus clairs et
engageants pour des pratiquants passionnés et des professionnels du secteur.
Objectif
Produire une newsletter textuelle (1200-1400 mots maxi), structurée, sans HTML,
basée sur les résultats d'une analyse du marché et de l'actualité.
Sections à couvrir (sans introduction ni conclusion) :
1. Tendances et conditions (enneigement, réglementations, événements)
2. Matériel et innovation (skis, fixations, sécurité DVA/airbags)
3. Sécurité et prévention (bulletins avalanche, formations, incidents)
4. Destinations et itinéraires (nouveaux parcours, refuges)
5. Marché et économie (fréquentation, nouveaux acteurs)
Format par section :
- Points clés : 4-6 puces avec chiffres et exemples datés
- Impacts pratiquants : 3-4 puces, format Impact : ... — Explication : ...
- Actions recommandées : 2-3 puces, verbes d'action concrets
Ton : clair, consultatif, factuel, style fluide comme un conseil entre passionnés.
Sources : au complet au format Titre de l'article – URL
Tâches : articles des 7 derniers jours uniquement, vérifier chaque URL,
ignorer les pages de tag/catégorie, supprimer les liens morts.
Pourquoi les blogs plutôt que les réseaux sociaux
J’ai fait un choix délibéré pour ma veille : privilégier les blogs et les sites spécialisés plutôt que les réseaux sociaux. La raison est simple : sur les réseaux sociaux, le bruit noie le signal. Vous cherchez une analyse approfondie sur la cybersécurité et vous tombez sur des threads de 280 caractères. Les blogs, c’est comme les bons livres des années 80 : plus longs à lire, mais le contenu a de la substance et un point de vue.
Au moment où j’écris ces lignes, vingt jours plus tard, ma veille comporte quinze étapes distinctes. Et sa dernière mise au point m’a fait exploser mon forfait de session en moins de deux heures. Mais ça, c’est une autre histoire.