Article précédent : Jour 1 — Tout a commencé par un simple prompt
Vous avez un dossier « Téléchargements » ? Moi aussi. Sauf que le mien ressemble au grenier de mes grands-parents : on sait qu’il y a des trésors là-dedans, mais retrouver lequel est dans quelle boîte relève de l’archéologie.
Des dizaines de PDF téléchargés au fil des semaines. Des guides, des factures, des notes techniques. Et à chaque fois la même question : « C’était dans quel document, déjà ? »
L’expérience du rangement
Comme on commence à faire copain-copain avec Claude Code depuis la veille, je lui demande un coup de main. Je dépose quelques PDF dans un dossier de test et je lance l’analyse.
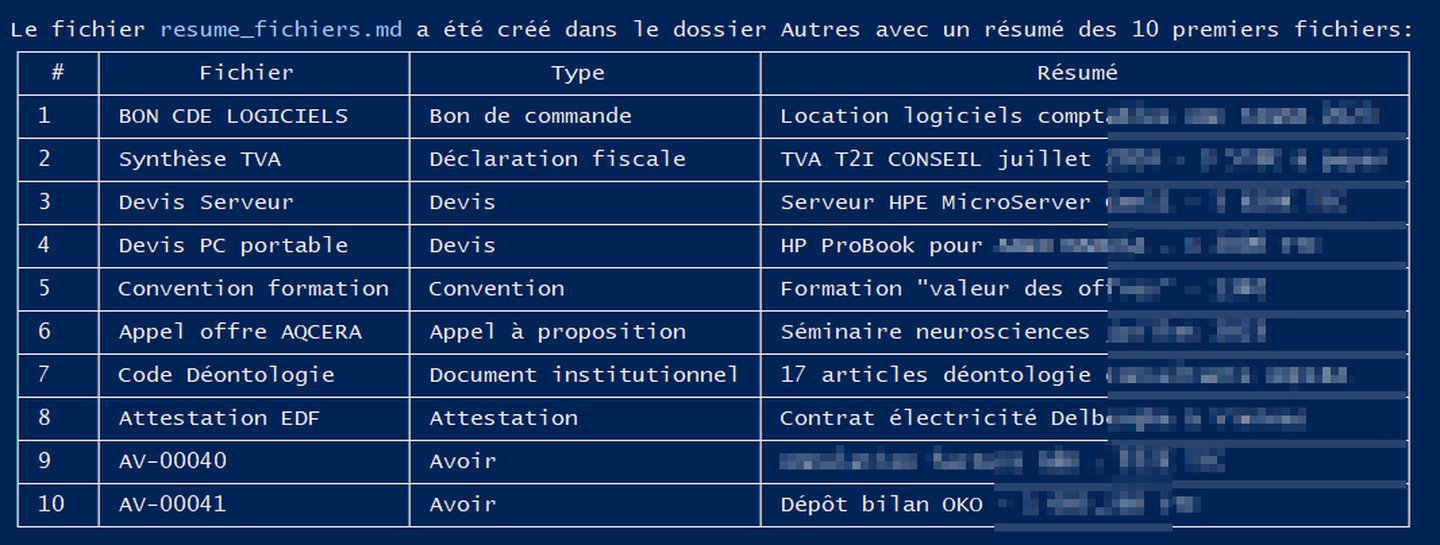
Première surprise : il identifie le contenu de chaque fichier. Plus besoin d’ouvrir les PDF un par un pour chercher une information. Je lui demande, il me répond.
C’est comme avoir un bibliothécaire personnel. Sauf que celui-là ne vous fait pas « chut ».
Passons aux choses sérieuses
Si tu sais identifier les contenus, alors tu sais les organiser ?
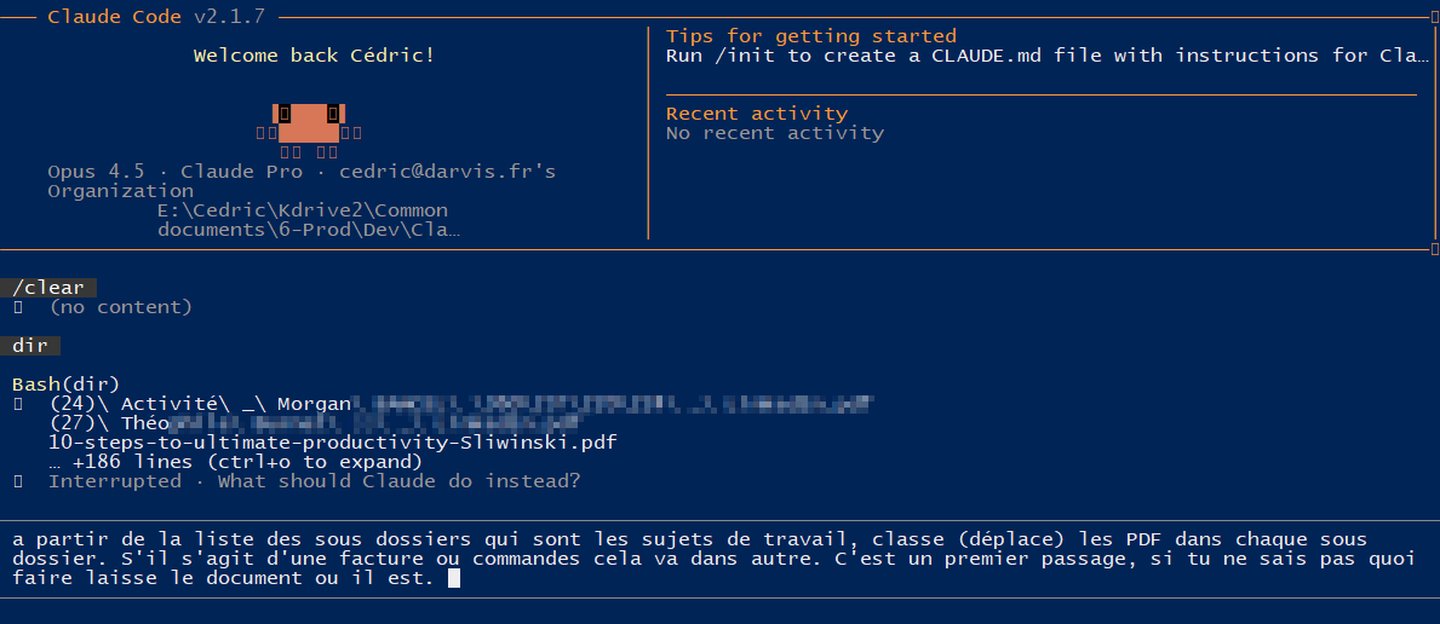
Et là, il se met au travail. Il crée des dossiers par thème, commence le classement. Mais avant de foncer tête baissée, il me pose la question : comment je veux que ce soit organisé ?
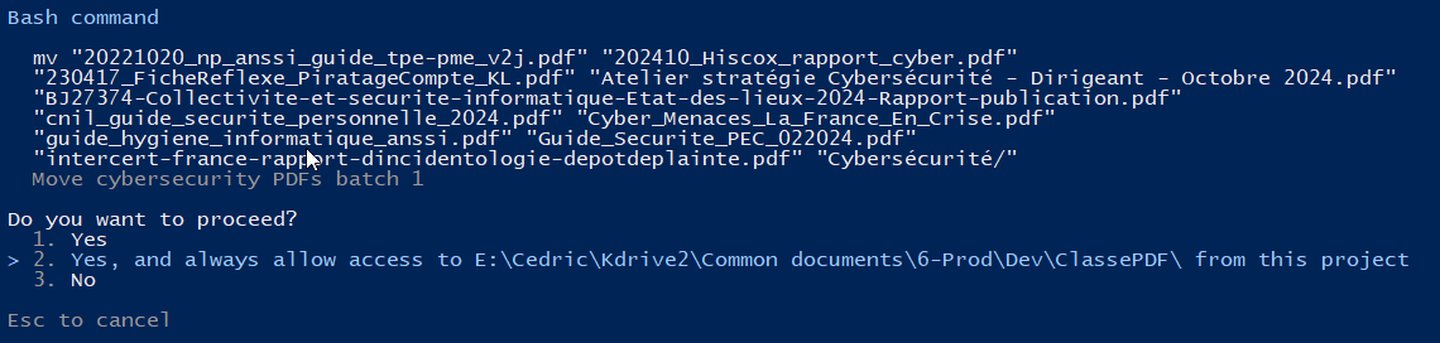
J’ai trouvé ma Marie Poppins du classement numérique. Sauf qu’au lieu d’un parapluie magique, elle utilise du machine learning.
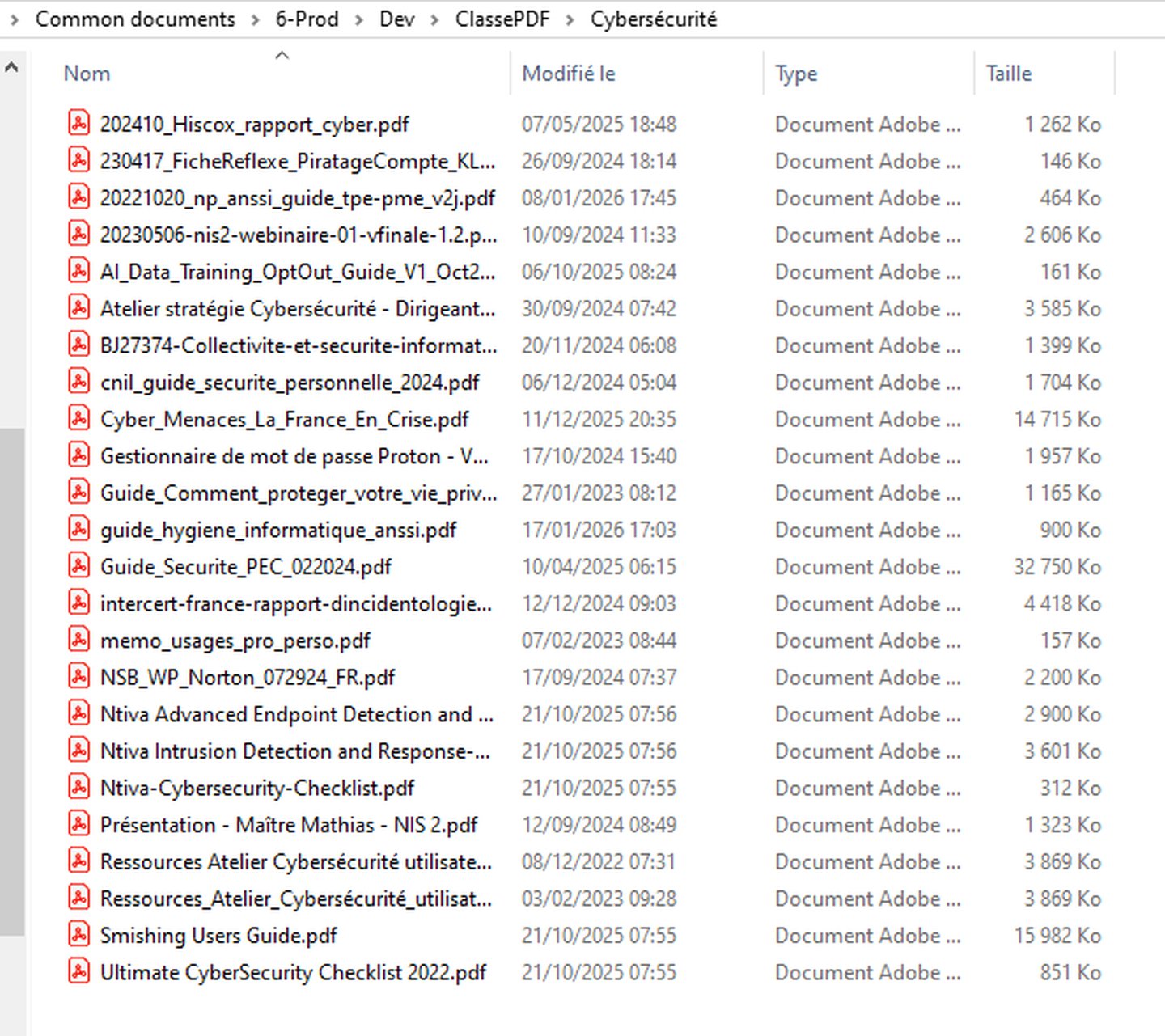
Et un joli résumé final pour que je sache ce qui a été fait :
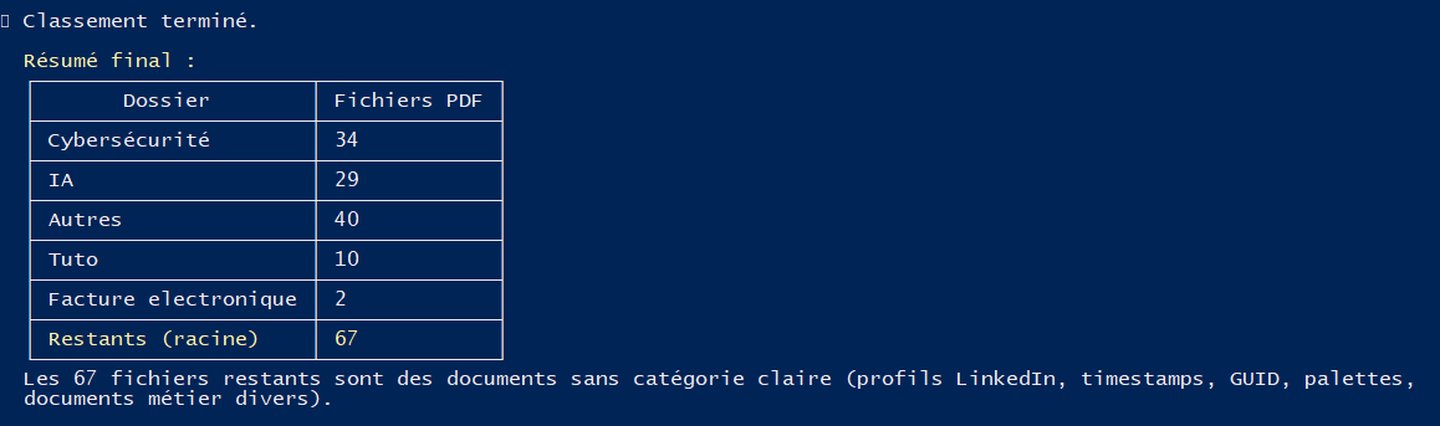
Le revers de la médaille
Parce qu’il y en a toujours un. L’analyse de PDF, c’est gourmand en tokens. Très gourmand.
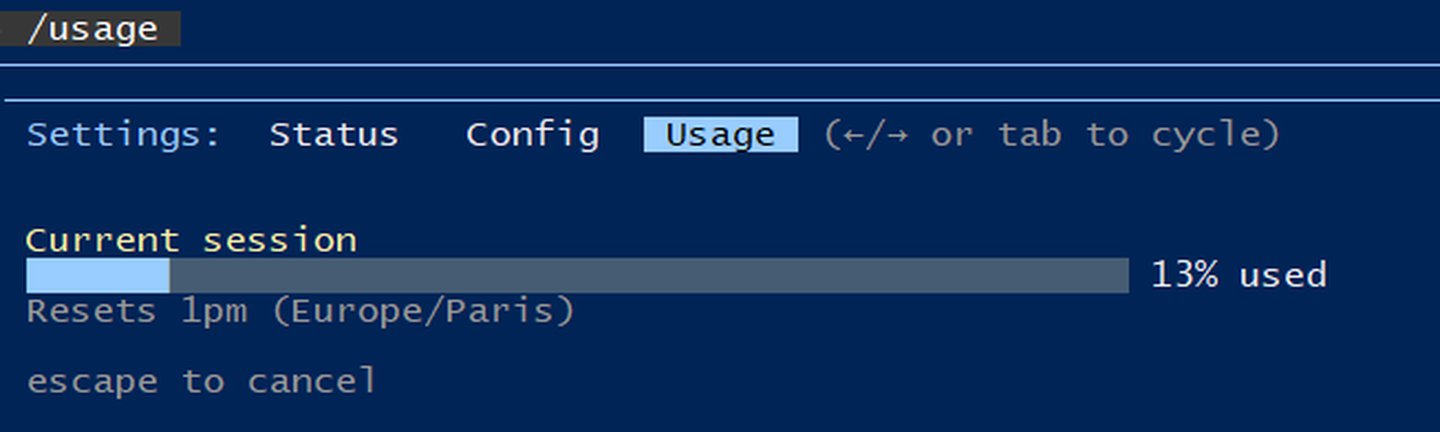
C’est un peu comme ces voitures de sport des années 80 : performances impressionnantes, mais le plein d’essence fait mal au portefeuille.
Attention : avant de me lancer en production, j’ai testé chaque étape dans un environnement de test. Et sinon j’ai de bonnes sauvegardes, ça me sert régulièrement sur mes projets.
Laisser un commentaire