J’avais une capture d’écran d’un prompt YouTube. Le genre de screenshot que vous prenez à la volée parce que la vidéo défile et que vous n’avez pas le temps de recopier. Sauf que maintenant, j’ai besoin du texte brut.
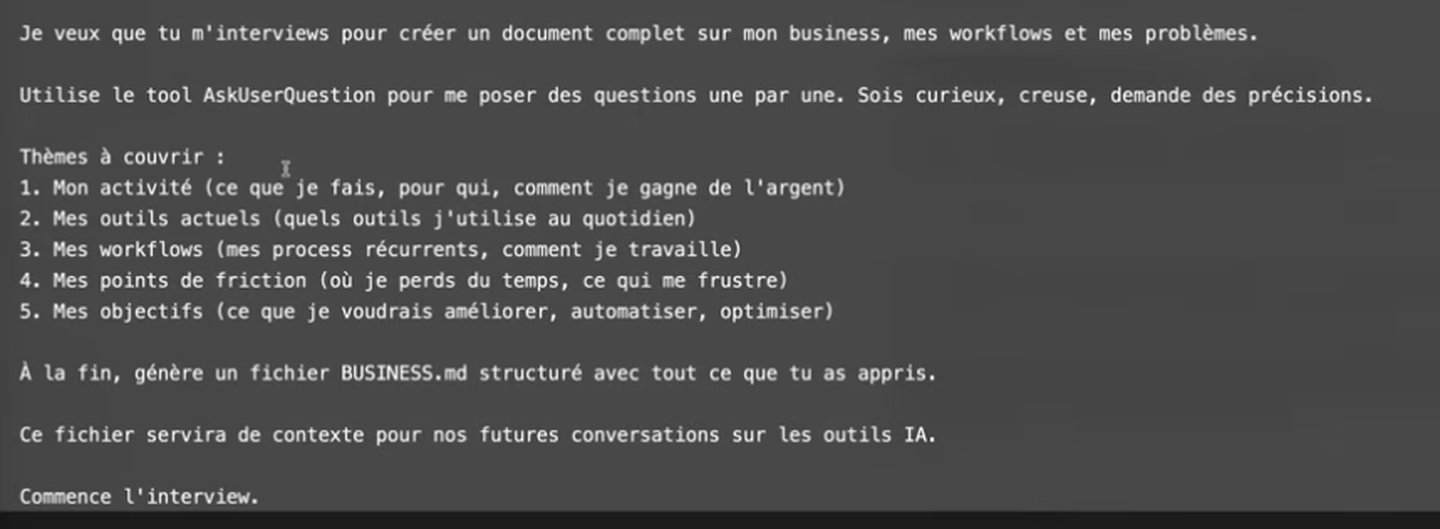
Premier réflexe : Ollama avec Deepseek-OCR. Un prompt tout simple, presque insultant de simplicité :
fait moi une reconnaissance du texteEt hop, en quelques secondes, l’image se transforme en texte exploitable. C’est beau, c’est rapide, ça marche.
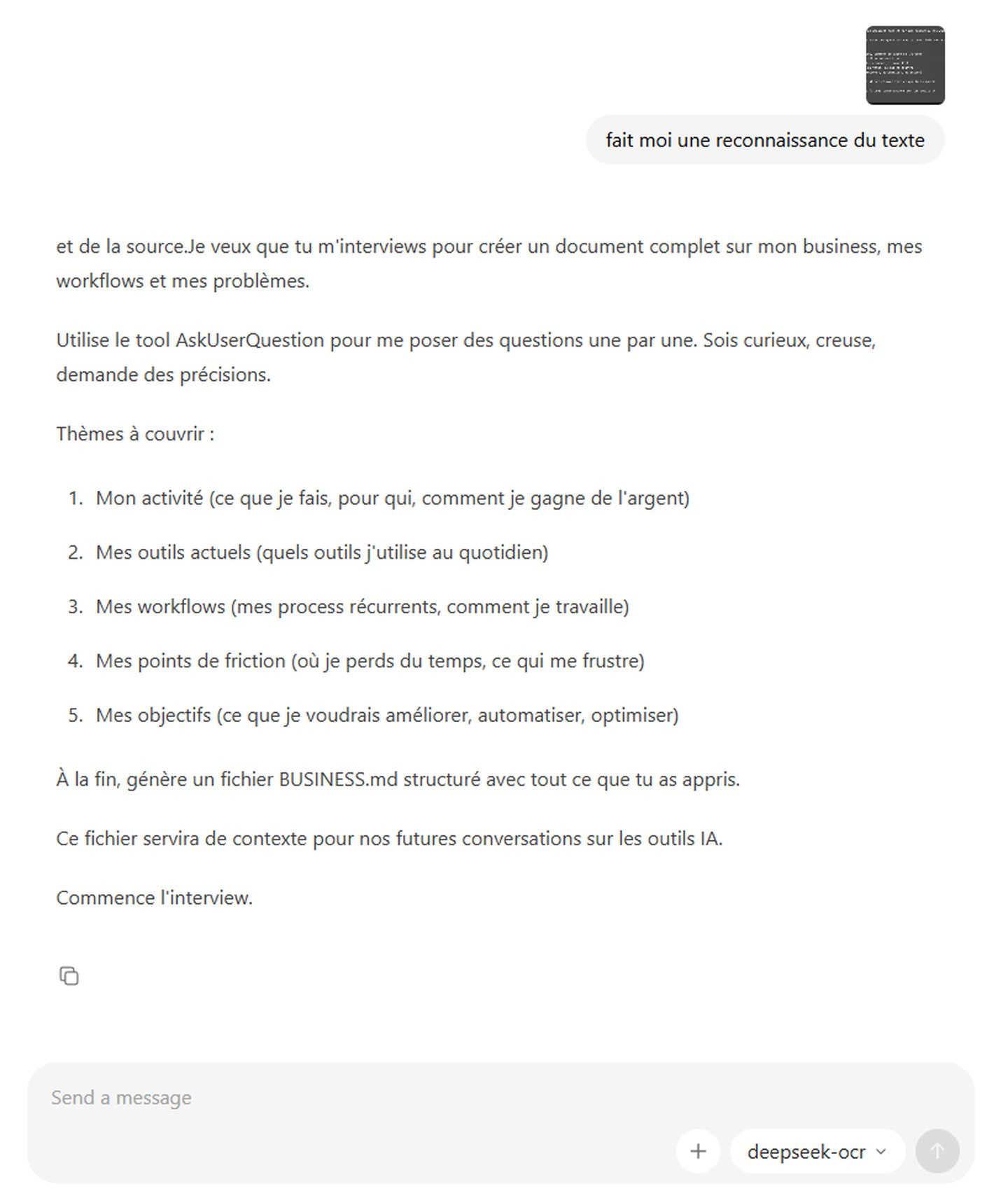
Évidemment, comme tout geek qui se respecte, je ne me suis pas arrêté là. J’ai voulu tester glm-ocr, le nouveau modèle supposé révolutionnaire. Celui dont tout le monde parle.
Résultat : impossible à installer localement.
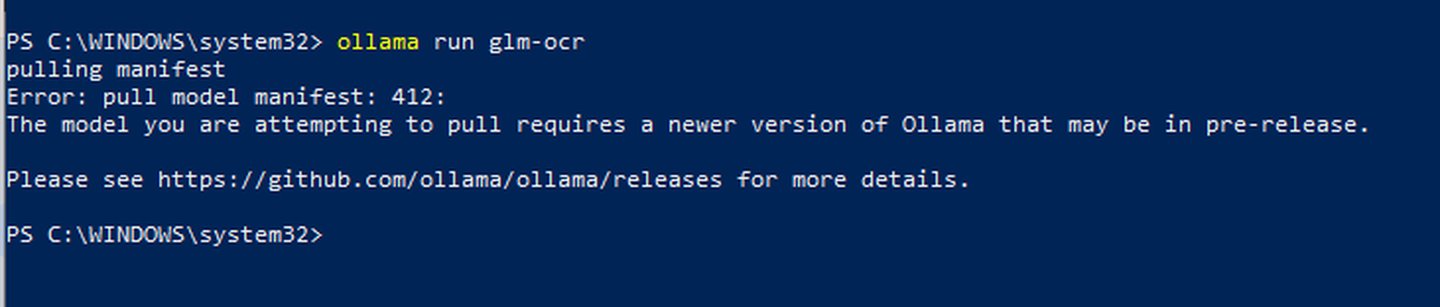
Vous connaissez la chanson. C’est comme ces vieilles cafetières italiennes qui font encore le meilleur café du quartier pendant que la nouvelle machine à dosettes refuse de démarrer parce qu’il lui manque une mise à jour firmware. Parfois, l’ancien marche mieux que le nouveau.
Et c’est là que le local prend tout son sens : pas de quota, pas de surprise tarifaire, pas de changement de conditions générales à 3h du matin. Juste votre machine qui bosse pour vous. Comme au bon vieux temps.
