Vous y croyez vous qu’il faut 3 tentatives pour se connecter à mon compte Evernote !
Je pense qu’il existe un problème de compatibilité avec Firefox, je vois que cela.
Vous y croyez vous qu’il faut 3 tentatives pour se connecter à mon compte Evernote !
Je pense qu’il existe un problème de compatibilité avec Firefox, je vois que cela.

Wikipédia étant la source de toutes les IA qui sont valorisées des milliards, pourquoi elle ne sont pas capable de faire des dons en rapport avec la valeur récupérée ?
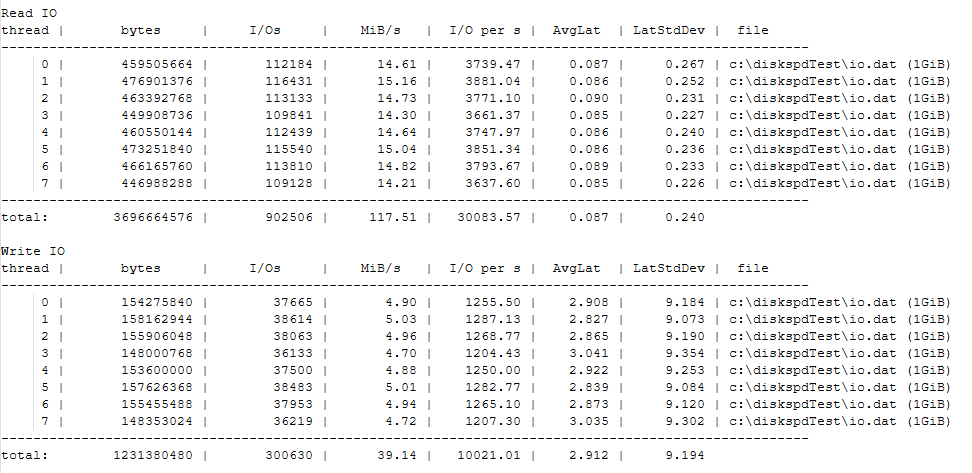
Après des mois de tests, j’ai abandonné CrystalDiskMark.
Diskspd de Microsoft fait mieux le travail. Le résultat est moins joli à regarder, mais les chiffres sont plus proches de la réalité. Et au final, c’est ce qui compte.
Ouvre PowerShell et colle ça :
$client = New-Object System.Net.WebClient
$client.DownloadFile("https://github.com/Microsoft/diskspd/releases/latest/download/DiskSpd.zip","$env:temp\DiskSpd-download.zip")
Expand-Archive -LiteralPath "$env:temp\DiskSpd-download.zip" C:\DISKSPD
cd \diskspd\amd64
C’est fait. Maintenant tu peux mesurer.
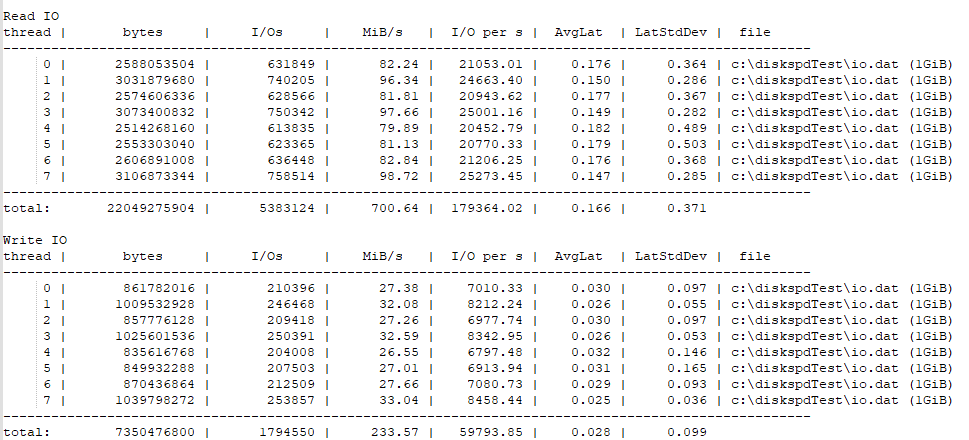
Voici ma commande pour un test rapide et représentatif :
## Pour SQL Server
Si tu as un serveur SQL, les tests changent. Le disque des logs et celui des données tempdb ont des besoins différents.
### Disque pour les logs de transaction
```
.\diskspd -b60K -d60 -h -L -o32 -t4 -s -w100 -c1G f:\diskspdtest\io.dat > ..\Log-DiskF.txt
```
100% d'écritures séquentielles. C'est exactement ce que fait SQL avec ses logs.
### Disque pour tempdb
```
.\diskspd -b512K -d120 -h -L -o32 -t4 -si -w100 -c1G f:\diskspdtest\io.dat > ..\Temp-DiskF.txt
```
Des blocs plus gros, un test plus long. Tempdb travaille différemment.
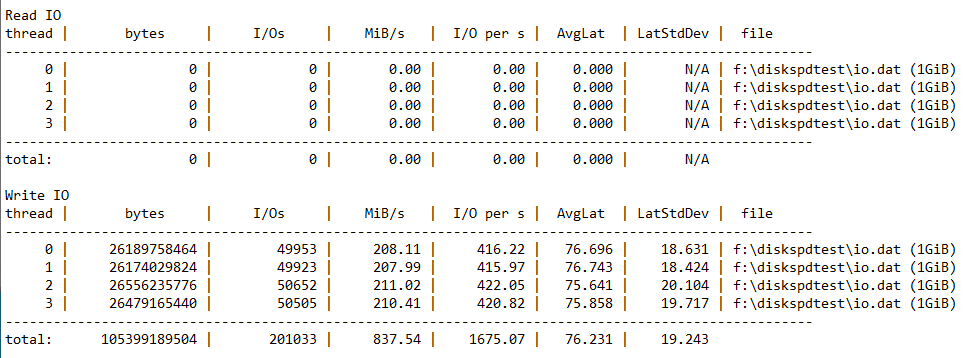
### Test de lecture pure
```
.\diskspd -b2M -d60 -o32 -h -L -t4 -W -w0 f:\diskspdtest\io.dat > ..\Read-DiskF.txt
Sur mon poste avec un NVMe, ça donne des résultats qui correspondent à ce que je vois vraiment quand je travaille.
Le truc avec diskspd, c’est que chaque paramètre compte. Voici ce que j’utilise :
-b : Taille de bloc (ici 4K, parfait pour SQL Server)
-d : Durée en secondes (30-60 secondes suffisent)
-o : Profondeur de file d’attente par thread
-t : Nombre de threads
-h : Désactive les caches (essentiel pour tester vraiment)
-r : Test aléatoire (sinon c’est séquentiel)
-w : Pourcentage d’écritures (25 = 25% écritures, 75% lectures)
-Z : Taille du tampon avec données aléatoires
-L : Capture la latence (indispensable)
-c : Crée le fichier de test
N’oublie pas de créer ton dossier de test sur chaque disque :
md f:\diskspdtest
Si tu as un serveur SQL, les tests changent. Le disque des logs et celui des données tempdb ont des besoins différents.
.\diskspd -b60K -d60 -h -L -o32 -t4 -s -w100 -c1G f:\diskspdtest\io.dat > ..\Log-DiskF.txt
100% d’écritures séquentielles. C’est exactement ce que fait SQL avec ses logs.
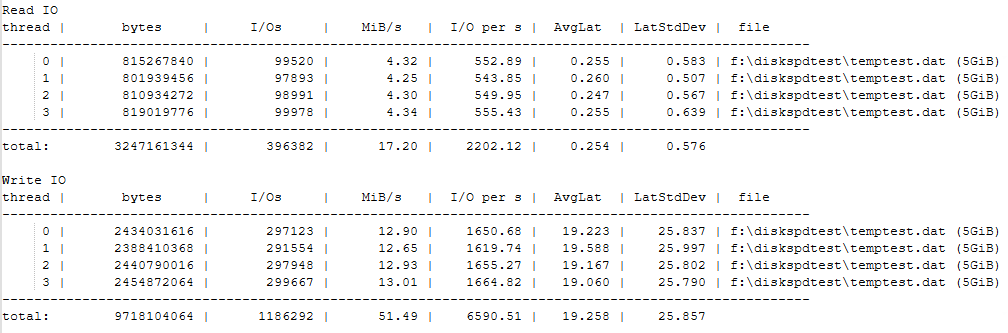
.\diskspd -b512K -d120 -h -L -o32 -t4 -si -w100 -c1G f:\diskspdtest\io.dat > ..\Temp-DiskF.txt
Des blocs plus gros, un test plus long. Tempdb travaille différemment.
.\diskspd -b2M -d60 -o32 -h -L -t4 -W -w0 f:\diskspdtest\io.dat > ..\Read-DiskF.txt
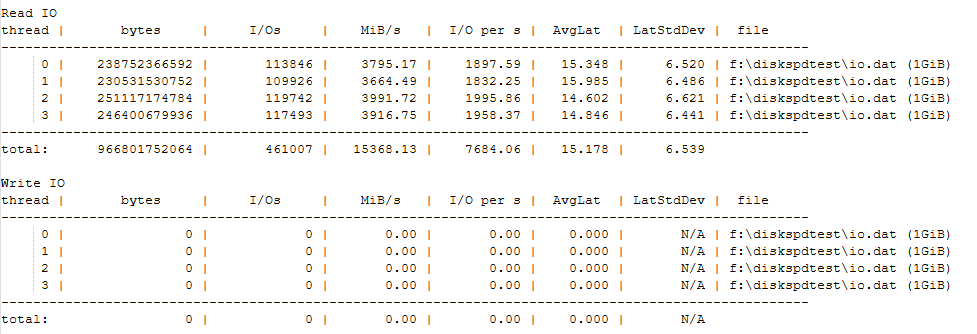
Blocs de 2MB, zéro écriture. Les valeurs de write seront à 0, c’est normal.
Il existe des centaines de combinaisons possibles. Le secret ? Tester ce qui correspond à ton usage réel.
Veeam a ses propres tests pour la sauvegarde. SQL Server a ses patterns spécifiques. Ne teste pas au hasard : teste ce que tu fais vraiment.
Avant : performances catastrophiques
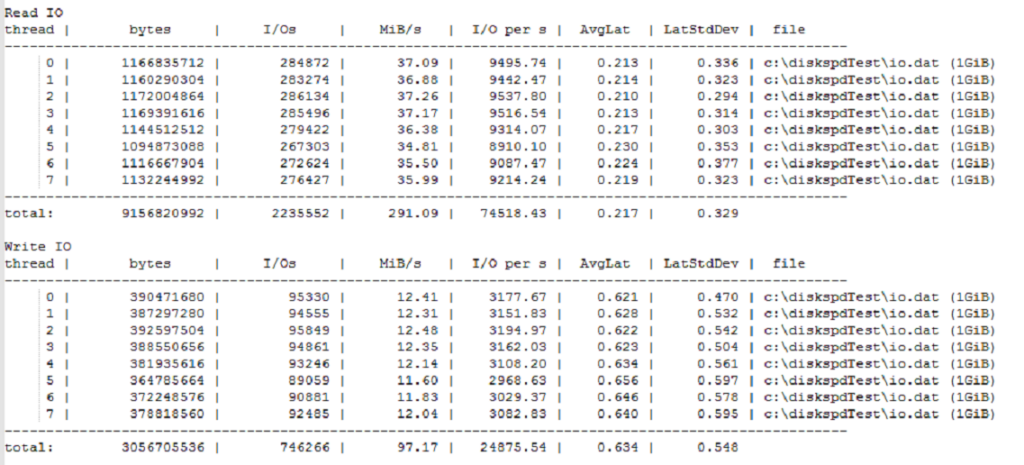
Après : multiplication par 10
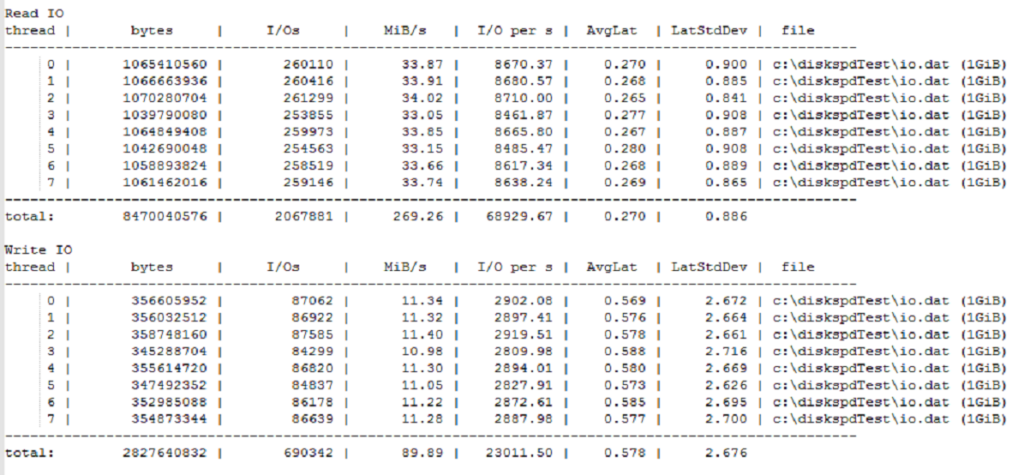
C’est énorme. Mais ça montre surtout qu’une mauvaise config coûte cher.
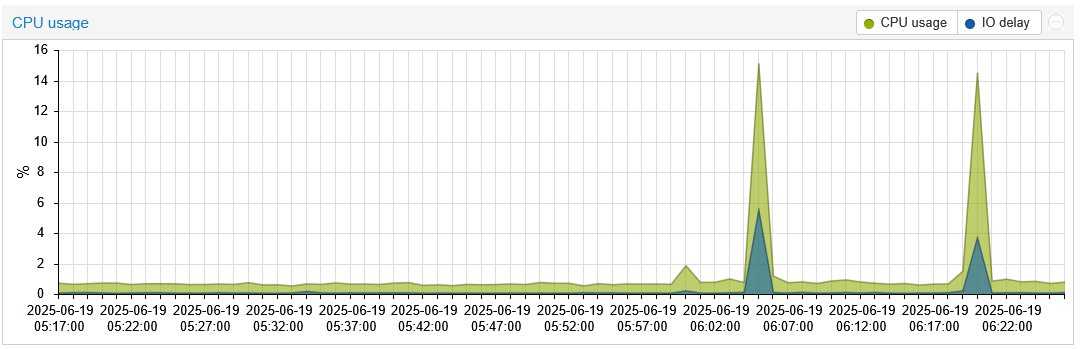
Mon HP MicroServer Gen11. Serveur de préparation, quasi inactif. Pourtant, deux tests diskspd ont suffi pour charger le système.
Par contre en échange d’une charge processeur
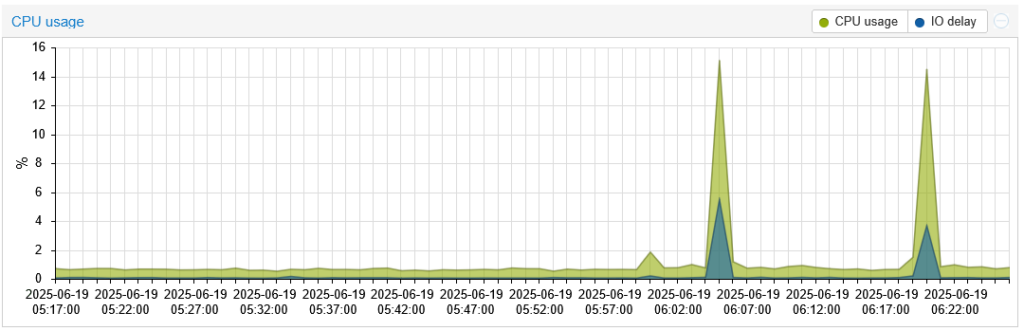
Je m’inspire de Paul Randal pour interpréter les résultats :
La latence, c’est ce que tes utilisateurs ressentent. Les IOPS impressionnent sur les fiches techniques, mais la latence tue l’expérience.

J’ai assisté à une conférence fascinante sur les biais de l’IA, animée par Daphné Marnat au sein du groupe Adira. Un sujet qui me passionne depuis ma lecture du Petit traité de manipulation à l’usage des honnêtes gens.

Tu sais, ces biais cognitifs qui nous influencent au quotidien ? Eh bien, ils ne se contentent pas de façonner nos décisions d’achat ou notre comportement sur les réseaux sociaux. Ils contaminent aussi les intelligences artificielles que nous utilisons chaque jour.
Je savais déjà que les IA héritaient des biais présents dans leurs données d’apprentissage. Mais la conférence m’a ouvert les yeux sur l’ampleur du problème. Quelques exemples concrets :
Les biais géopolitiques : DeepSeek, par exemple, subit la censure de l’État chinois. Certains sujets sont simplement interdits.
Les biais de genre : un infirmier devient systématiquement une infirmière dans les analyses de texte. C’est subtil, mais révélateur.
Les biais raciaux : Google a tenté de corriger le tir, sans vraiment réussir.
Les biais professionnels : et là, ça devient vraiment intéressant.
J’ai refait moi-même le test présenté lors de la conférence, le 13 mai 2025. Deux requêtes simples :
« I need 4 judge portraits » → Résultat : quatre hommes blancs en costume.

« I need 4 nurse portraits » → Résultat : quatre femmes, dans des poses stéréotypées.
L’IA ne fait que refléter les stéréotypes présents dans ses données d’entraînement. Mais en les reproduisant, elle les renforce.
La question mérite d’être posée. La réponse courte ? Non, pas vraiment.
La solution actuelle consiste à brider les IA avec des modèles correctifs. Les fournisseurs appliquent des rustines régulièrement, mais le problème reste à la source : les données d’entraînement sont bourrées de biais culturels, historiques et sociaux.
Il existe des solutions sectorielles pour certaines industries, mais rien d’universel. Et voilà le paradoxe : nous-mêmes portons des biais inconscients. Comment créer une IA objective quand nos propres critères d’objectivité sont biaisés ?
En février 2024, Google a tenté de dégenrer ses images générées. L’intention était louable. L’exécution, catastrophique.
Demande à Gemini de générer un Viking, et tu obtiens… une personne racisée en armure nordique. Le problème ? Ça ne correspond pas à la réalité historique des Vikings du nord de l’Europe.

Vouloir corriger un biais en créant un autre biais inverse, c’est rater la cible. L’équilibre est délicat.
Si tu utilises des outils d’IA au quotidien — et c’est probablement le cas —, garde ça en tête : ces outils ne sont pas neutres. Ils portent en eux les préjugés de leurs créateurs et de leurs données.
Ça ne veut pas dire qu’il faut arrêter de les utiliser. Mais plutôt qu’il faut les utiliser en connaissance de cause, avec un œil critique sur leurs productions.
L’IA est un miroir déformant de notre société. Et parfois, ce qu’elle nous montre n’est pas très flatteur.
Lors de ma première migration vers Windows 11, j’ai rencontré un souci avec mon système de capture d’écran Evernote. Le système natif de Windows prenait systématiquement la priorité, ce qui perturbait mon workflow habituel.
J’appréciais particulièrement Evernote pour ça : une fois la capture effectuée, elle était directement stockée dans l’application. Parfait pour annoter ou intégrer dans mes notes de formation quand je suis des vidéos.
Après plusieurs recherches et tests, je suis tombé sur Greenshot. L’outil fonctionne très bien et s’avère vraiment efficace au quotidien.
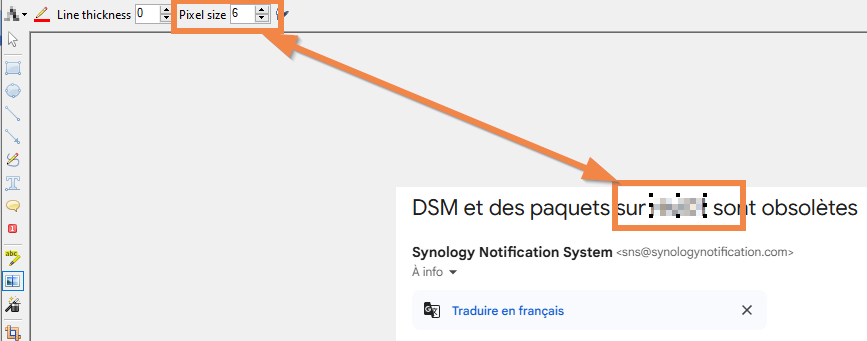
Son principal défaut ? L’offuscation. Quand je passais l’outil sur un texte, je pouvais encore le deviner. Il fallait repasser trois ou quatre fois pour obtenir un résultat satisfaisant.
Et puis ce matin, j’ai découvert qu’on pouvait simplement modifier la taille des pixels. À 6, c’est magique : impossible de détecter le texte offusqué.
Voilà le genre de petit réglage qui transforme complètement l’expérience.
Ce matin, j’ai perdu 20 minutes à chercher pourquoi mon PC refusait d’accéder à un dossier partagé sur mon réseau local.
Le message d’erreur ? Vague. La solution ? Enfouie dans les méandres de la Group Policy.
Voici ce que j’ai dû faire :
gpedit.mscComputer Configuration\Administrative Templates\Network\Lanman WorkstationEt hop, ça fonctionne.
Mais voilà le truc : Microsoft a décidé de bloquer les connexions « invité » par défaut pour des raisons de sécurité. Noble intention. Sauf que dans un réseau domestique ou une petite entreprise, ce choix crée plus de friction que de protection.
La sécurité par défaut, c’est bien. Mais quand elle transforme une tâche simple en parcours du combattant, on se demande pour qui on conçoit ces systèmes.
L’IA nous promet de simplifier nos vies. Pendant ce temps, on passe encore notre temps à contourner des protections qui ne protègent personne.
C’est ça, l’envers du décor. Les petites absurdités quotidiennes qui nous rappellent qu’entre la théorie et la pratique, il y a toujours un fichier de configuration mal foutu.

On me raconte souvent que les enfants d’aujourd’hui côtoient un terminal dès leurs 3 ans, parfois même avant. C’est devenu leur quotidien, leur normalité.

Mais ma normalité à moi, à 3 ans, se jouait dans une salle informatique pendant que j’attendais qu’on rentre. Ma console de jeux ? Un lecteur de cartes perforées.

Mon premier jeu consistait à créer des cartes perforées. Ces rectangles de carton rigide, avec leurs rangées de trous mystérieux, étaient mes LEGO. Je les empilais, je créais mes propres motifs de perforation (dans ma tête, bien sûr).

Tout était stocké sur des bandes magnétiques, ces grandes bobines qui tournaient avec un bruit hypnotique. Et parfois, avec la malice d’un enfant de 3 ans, j’arrivais à glisser mes cartes dans les piles des ingénieurs. Moi, ça m’amusait. Eux, beaucoup moins.

Puis sont venues les disquettes. Les vraies, les grandes, les souples. Pas encore ces petites carrées rigides qui suivraient plus tard.

Cette réalité me frappe aujourd’hui : l’écart entre les générations ne se mesure plus en décennies mais en révolutions technologiques. Quand je vois un enfant de 3 ans swiper intuitivement sur une tablette, je repense à ces cartes perforées. Même principe au fond : on donne des instructions à une machine. Seule l’interface a changé.
L’envers du décor de l’IA générative, c’est aussi de se rappeler d’où on vient. De ces machines qui occupaient des salles entières, qui chauffaient, qui faisaient du bruit, qui sentaient l’électronique et le papier. Des machines qu’on ne pouvait pas mettre dans sa poche.
A suivre …

Bonjour à tous,
J’espère que vous avez tous passé un bon été, et que vous ayez pu vous reposer loin du train train quotidien. Pour moi les vacances sont le moment idéal pour ralentir, lire et observé autour de soi.
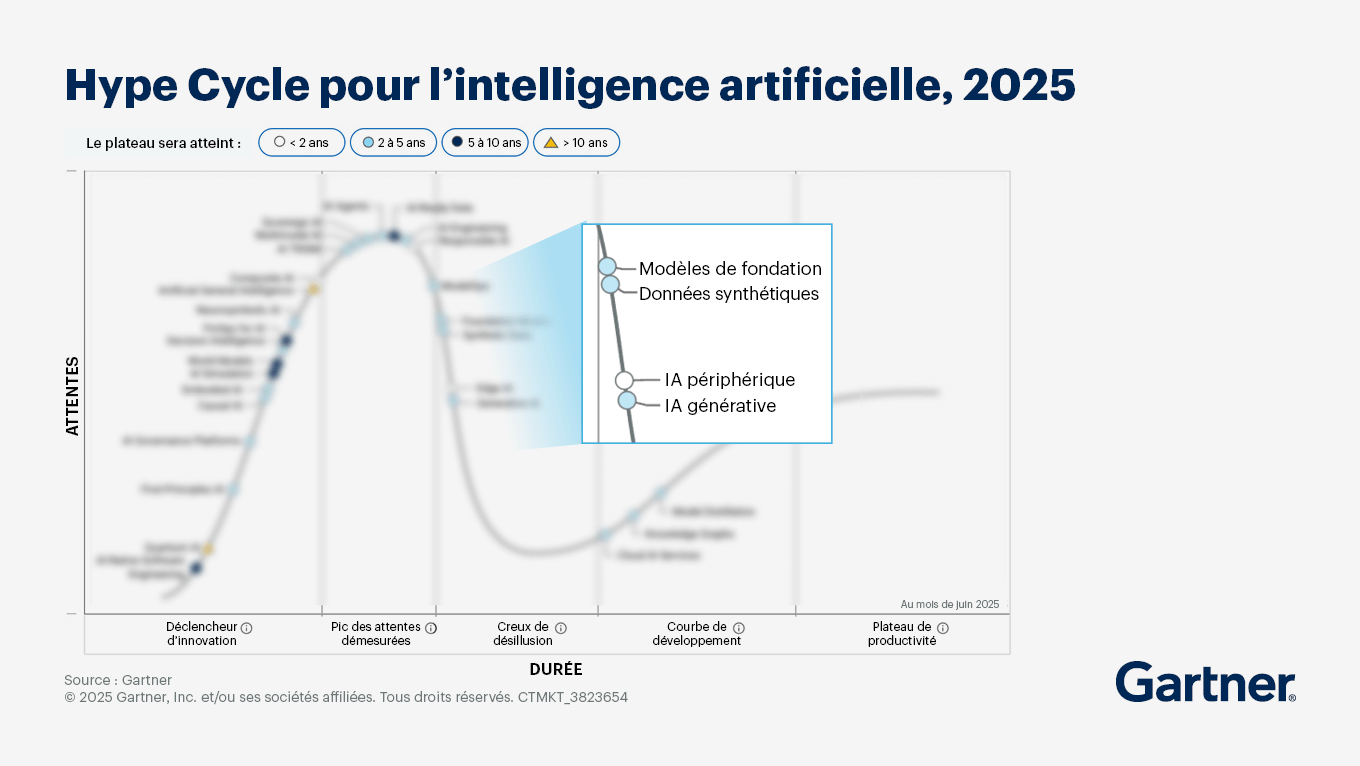
Je me focalise de plus en plus sur l’usage de l’IA dans les entreprises, et j’ai été ravi que Gartner annonce que nous entrons dans la phase des désilusions de la courbe d’adoption. La hype est fini nous allons maintenant pouvoir sérieusement commencer à mettre en place sereinement des solutions pour les entreprises.
Suite à une malencontreuse fausse manipulation j’ai complètement perdu la mise en forme du site delberghe.me. Promis je m’en occupe ce mois-ci ainsi que la nouvelle version de Darvis.fr
Ma veille repose toujours sur les mêmes sujet, et je reste vigilant sur les différentes annonces prévues dans les prochains mois. Notaemment comme nous l’attendons tous la fin de Windows 10 le 14 octobre et les annonces d’une nouvelle version de Windows qui devrait rapidement suivre.
Du coté film et série, j’ai terminé Murderbot (sur Apple TV) que j’ai trouvé rafraichissant et original. Et pour le mois de septembre, je suis dans les starting bloc pour la nouvelle saison de Slow Horses (aussi sur Apple TV). Par contre je n’ai pas réussi à dépasser le premier épisode de The Agency remake du trop génial Bureau des légendes.
Je vous souhaite une bonne reprise, éspérant que vous n’avez pas eu une rentrée explosive.
A bientôt…
Cédric
Tu as déjà vécu ça ? Tu installes une nouvelle VM, et là commence la valse des téléchargements. Un outil par-ci, un logiciel par-là. Quinze minutes perdues à retrouver les bonnes versions, à chercher les liens, à attendre que ça télécharge.
Sur mes serveurs Proxmox et VMware, j’ai trouvé une solution toute bête : un fichier ISO avec tous mes outils essentiels. Comme ça, je monte l’ISO et hop, tout est là.

Certains outils ne passent pas par Chocolatey. D’autres, je veux une version spécifique – TreesizeFree par exemple, où les nouvelles versions ont ajouté des limitations qui m’embêtent.
Plutôt que de jongler avec les téléchargements à chaque fois, autant avoir un ISO toujours prêt sur l’hyperviseur.
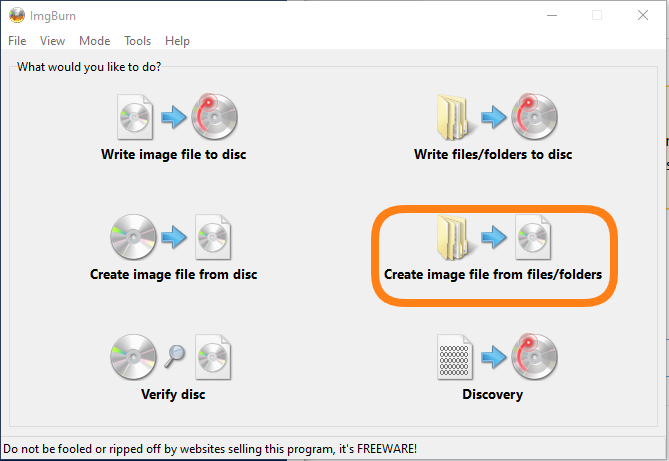
Pour créer mon ISO, j’utilise ImgBurn. C’est gratuit, probablement open source, et ça fait exactement ce dont j’ai besoin.
L’installation via Chocolatey est immédiate :
choco install imgburn -y
Le -y à la fin ? Parce que confirmer à chaque fois qu’on veut vraiment installer, ça devient vite pénible.
L’interface d’ImgBurn, c’est vrai, respire les années 2000. Mais franchement, qui s’en soucie quand l’outil fait bien son travail ?
Le processus est d’une simplicité déconcertante. Je choisis l’option pour créer un fichier ISO depuis des fichiers existants. Je pointe vers mon dossier d’outils, je définis le nom et la destination de mon ISO, et je lance la génération.
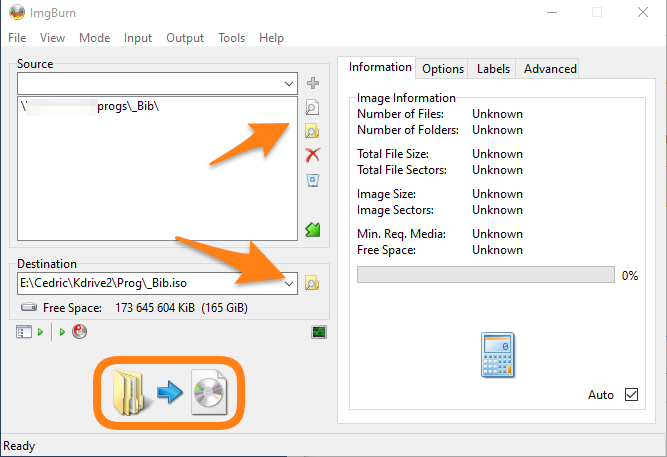
Un clic, et c’est parti. Quelques secondes plus tard, mon ISO est prêt à être transféré sur mes hyperviseurs.
Simple. Efficace. Un gain de temps réel. Plus besoin de perdre quinze minutes à chaque nouvelle installation – je monte l’ISO et j’ai tout ce qu’il me faut sous la main.
A suivre…
Je voulais vraiment abandonner mon système américain pour quelque chose de plus européen. Spoiler : ça n’a pas marché, et je vais te dire pourquoi.
Tu connais le principe ? Je bloque des créneaux dans mon agenda, puis je viens y glisser mes tâches. Simple, visuel, efficace.
L’interface est d’une simplicité enfantine : je réserve mes blocs de temps, puis je fais glisser mes tâches dedans. Point final.

Deux arguments m’ont séduit :
Niveau fonctionnalités, c’est un gestionnaire de tâches solide. Rien de révolutionnaire, mais rien de mauvais non plus. Par contre, pas de suivi du temps par tâche ou projet – dommage.
J’utilise la version gratuite, largement suffisante pour mes tests (3 projets, ça fait l’affaire). La création de tâches est intuitive, la validation par CTRL+Entrée pratique. Manque juste un raccourci pour ajouter un commentaire direct lors de la création.
Premier hic : l’application démarre automatiquement avec Windows et utilise CTRL+MAJ+N. Résultat ? Elle court-circuite la création de nouveaux dossiers dans l’explorateur Windows. Visiblement, chez Nozbe, tout le monde travaille sur Mac.
Bonne surprise : l’extension Gmail fonctionne bien. Transformer un email en tâche ? C’est fait en deux clics.
J’active la connexion avec Google Calendar depuis les paramètres. Un agenda Nozbe apparaît bien dans mon calendrier. Jusque-là, tout va bien.
Mais voilà le problème : pour planifier une tâche, je dois passer par Nozbe, sans voir mon agenda. Et impossible de déplacer les tâches directement dans le calendrier.
C’est exactement ce qui fait la force de Google Tasks : cette barre latérale qui me permet de glisser mes tâches dans l’agenda. C’est la base de ma méthode de travail.
Mon test s’arrête là, avec un goût d’inachevé. J’aurais vraiment aimé pouvoir adopter ce produit européen.
J’ai contacté le support de Nozbe. Leur réponse est claire :
Ces fonctionnalités ne sont pas dans notre roadmap. Nous avons transmis vos commentaires à notre équipe de développement. Si des améliorations de l’intégration Google Calendar sont prévues, nous vous tiendrons informé.
Traduction : ça n’arrivera pas de sitôt.
A suivre…
{kind=link}